








Failover clustering
High availability, scalable, virtualisation and storage failover cluster
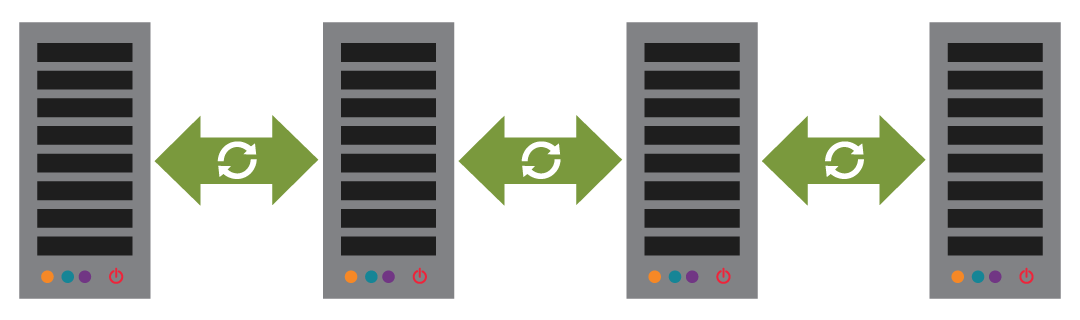
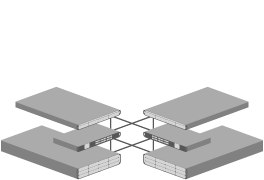
A converged server cluster, or shared storage cluster, integrates multiple discrete hardware components into a single close infrastructure to create a versatile, high availability computing and storage framework. Application usage is virtualised, with shared (and usually replicated) storage.
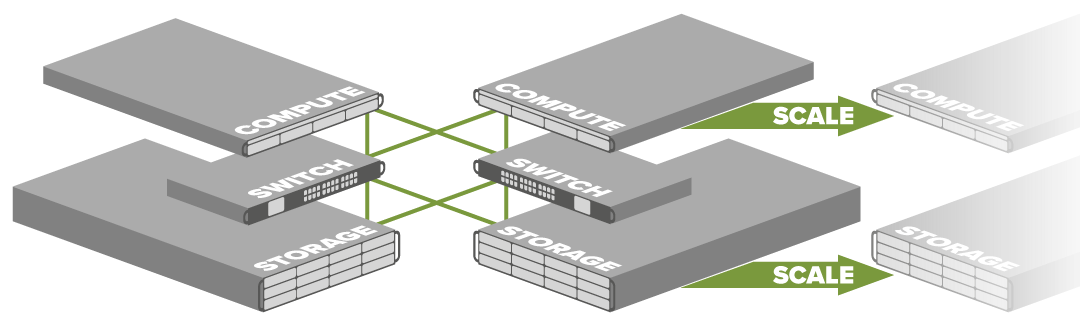
Components making up a typical shared storage cluster comprise:
- Compute servers
- Storage servers or JBODs
- Network switches
- Control software
Compute and storage nodes are located in separate physical tiers interconnected by switching gear. The separation of compute and storage allows for flexible scaling to boost performance, increase storage or multiple redundancy as usage and policy demand.
The simplest shared storage cluster would be made up of 2 failover compute nodes acting as hypervisors running sets of virtual servers, connected to a single shared storage node. More typically, there would be 2 or more replicated storage nodes so that data is also highly available in case of node failure.
Features and benefits of implementing a shared storage cluster
- High availability
Failover compute and replicated storage nodes mean control and data remain operational even in the event of node failure. - Scalable availability
Adding more redundant nodes increases the number of simultaneous node failures that can be tolerated. - Automatic rebuilding
Following node failure, after physical remedial work has been completed, a failed storage node will automatically rebuild its unsynchronised data to restore full redundancy. - Scalable infrastructure
Compute performance or storage capacity can be scaled independently by the addition of further nodes in either tier. - Extra redundancy
Separation of compute and storage nodes means these functions are independently redundant too.
- Reduce downtime
With failover compute and replicated storage, infrastructure is no longer vulnerable to a single point of failure. In the event of node failure, VMs failover to another compute node and storage volumes are immediately switched to synchronised copies with minimal downtime. - Reduced capital costs
Virtualisation and shared storage consolidate traditionally distributed applications into a single hardware framework. Fewer physical servers are required to create a complete infrastructure, saving on hardware costs. - Reduced operating costs
Less hardware means smaller power overheads and maintenance costs. Software controlled virtual infrastructure centralises and simplifies server management meaning far more can be achieved in far fewer working hours.